AI Models' Ability to Perform Tasks Doubles Every Seven Months
If the trend continues, we will see AI models capable of performing an entire day's work by 2026-27 and month-long projects by the end of 2030.
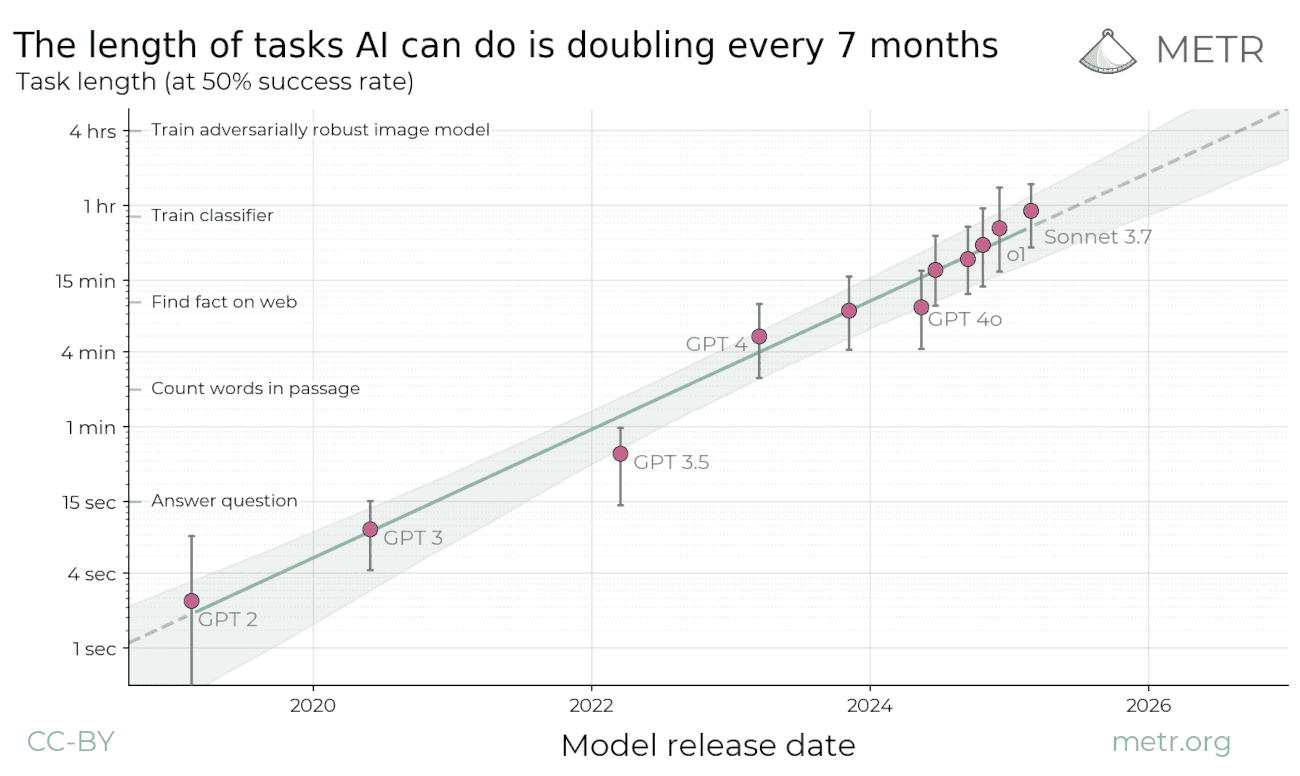
The research centre METR has investigated how long tasks different AI models can solve without making errors. Task length is measured against how long a human expert would take to complete the same task — for example, the time it takes to answer a question versus building a website from scratch.
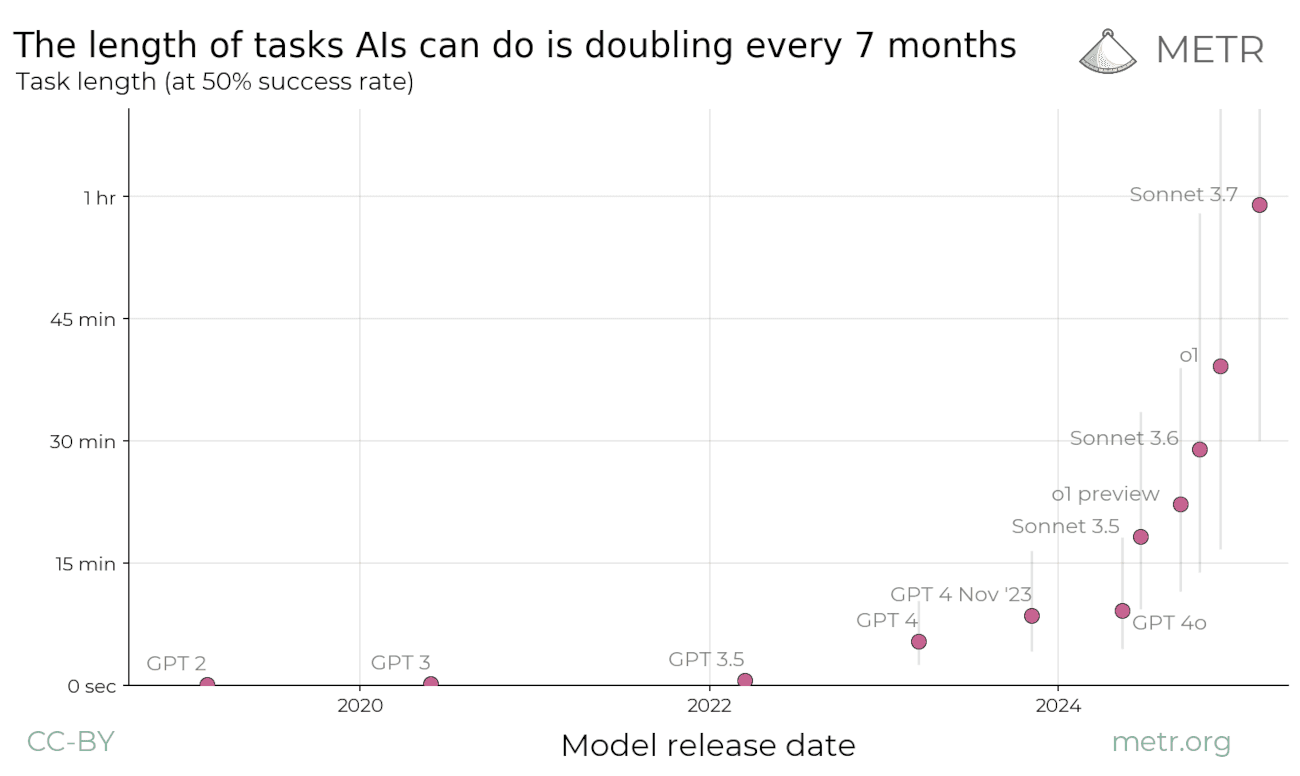
METR looks all the way back to GPT-2 in 2019, which could only solve tasks that took less than three seconds. Since then, models have only grown more powerful, and Anthropic's latest model can now solve tasks that take an hour. Note that the graph is logarithmic (i.e. goes from 1 sec, to 4 sec, to 15 sec, etc.). If you look at the linear version, you can see more clearly that the growth is exponential.
METR's research explains an important paradox: Today's AI models can outperform humans on complex knowledge tests, yet struggle to assist with ordinary work. The reason is that most practical tasks require multiple consecutive steps that build on each other. Even though AI is fantastic at individual steps, even a small error rate per step means the probability of completing the entire chain successfully drops dramatically.
Up until now, the length of tasks models can solve has approximately doubled every seven months. How will this develop going forward? If the trend continues, we will see AI models capable of performing an entire day's work by 2026, and month-long projects by the end of 2030.
This could have major consequences for our society in terms of research and economics. At the same time, the trend could become even steeper or flatten out. METR's research only deals with historical data. We do not know what the future holds.
It should be emphasised that the research has a number of limitations and assumptions that one may disagree with. For example, the tasks they measure differ significantly from tasks one would encounter in the real world. If you want to read more, I recommend checking out Shakeel Hashim's analysis at Transformer or reading METR's own paper.