KI-modellers evne til å utføre oppgaver dobler seg hver syvende måned
Om trenden fortsetter, vil man få KI-modeller som kan utføre et helt dagsarbeid innen 2026-27 og månedslange prosjekter innen utgangen av 2030.
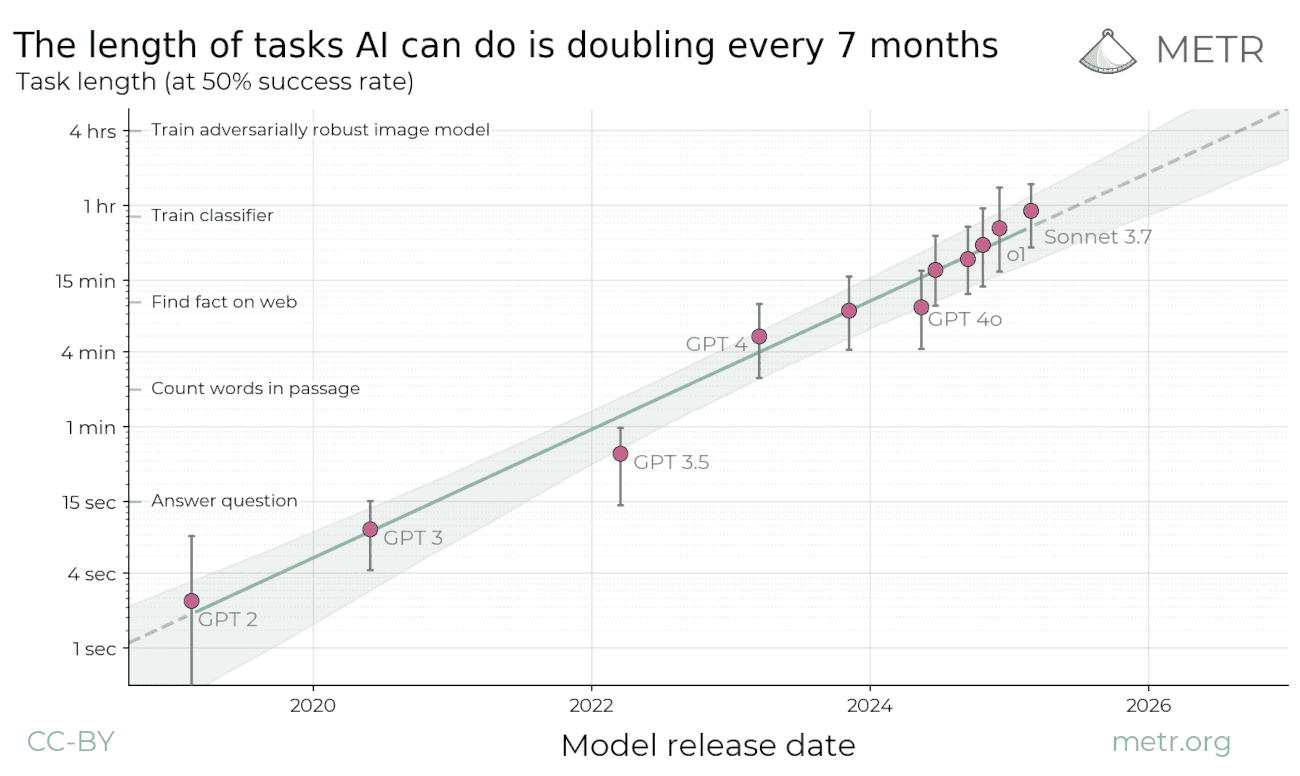
Forskningsenteret METR har undersøkt hvor lange oppgaver forskjellige KI-modeller klarer å løse uten å gjøre feil. Lengden på oppgaven er målt opp mot hvor lang tid en menneskelig ekspert ville brukt på samme oppgave, som for eksempel tiden det tar å svare på et spørsmål eller telle ord i et avsnitt.
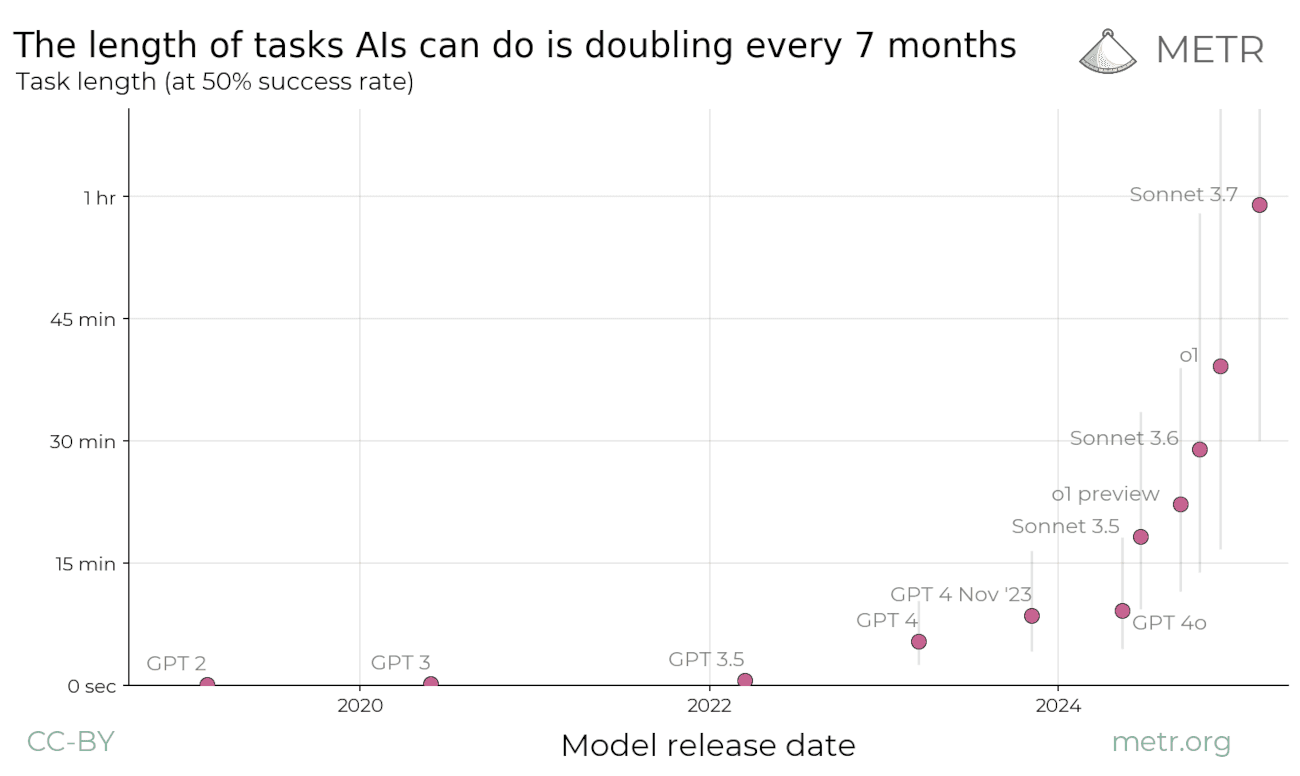
METR ser hele veien tilbake til GPT 2 i 2019, som bare klarte å løse oppgaver som tok mindre enn tre sekunder. Siden den gang har modellene bare blitt kraftigere, og Anthropics siste modell klarer nå å løse oppgaver som tar en time. Legg merke til at grafen ovenfor er logaritmisk (dvs. går fra 1 sek, til 4 sek, til 15 sek osv.) Om man ser på den lineære versjonen, ser man tydeligere at veksten er eksponentiell.
METRs forskning forklarer et viktig paradoks: Dagens KI-modeller kan slå mennesker på kompliserte kunnskapstester, men sliter med å hjelpe til i vanlig arbeid. Årsaken er at de fleste praktiske oppgaver krever flere sammenhengende steg som bygger på hverandre. Selv om KI er fantastisk på enkeltoppgaver, mister den ofte tråden i lengre sekvenser.
Fram til nå har lengden på oppgaver modellene klarer å løse, doblet seg omtrent hver syvende måned. Hvordan vil det utvikle seg framover? Om trenden fortsetter, vil man få KI-modeller som kan utføre et helt dagsarbeid innen 2026, og månedslange prosjekter innen utgangen av 2030.
Det vil i så fall kunne ha store konsekvenser for samfunnet vårt når det gjelder forskning og økonomi. Samtidig kan hende at trenden blir enda brattere eller flater ut. METRs forskning forholder seg bare til historiske data. Vi vet ikke hvordan framtiden vil bli.
Det må understrekes at forskningen har en rekke begrensninger og antakelser som man kan være uenig med. For eksempel skiller oppgavene de måler seg en del fra oppgaver man vil møte i den virkelige verden. Om du vil lese mer, anbefaler jeg å sjekke ut Shakeel Hashims analyse på Transformer eller å lese METRs egen artikkel.